
时间:2020年12月27-29日
地点:南京大学文学院
各位领导、各位专家:
上午好!
非常感谢主办方的邀请,让我有这么一个机会在这里与大家交流。我衷心祝贺《江苏文库》第三期成果成功问世!根据我的初步的调查,浙江和江苏的著述应该占全国著述总量的60%左右。浙江古代文献的大规模整理,应该说比江苏起步早。但是,经过这几年的发展来看,江苏的文献整理有后来居上之势。我认为浙江文献整理的机制上还存在问题,主要是规划办、高校、出版社、图书馆之间的关系没有处理好,当然还有其他的问题。不过,前不久浙江省规划办领导找到我,表达了规划办与浙大共建浙江文史大数据平台的愿望。这样的话,浙江古代文献整理与江苏就能够齐头并进。中国古代文献的整理,我认为最后应该会走到智慧化数据的阶段。所以我今天报告的题目是《大数据背景下的地方文献整理》。
首先,介绍一下《浙江古代文献总目》的编纂情况。这是我与另一个教授负责的项目,已进行了15年的时间,今年已经结项。根据我们初步的调查,《浙江古代文献总目》经部2500多条,史部有13700多条,子部9000多条,集部14000多条,丛部500多条,总字数有400百多万字。我们根据评审专家的意见,还要进一步完善,争取明年出版。这是我们的样子,我们分类,有书名、籍贯、作者、收藏地、版本等等信息,根据我们现代图书馆的一个著录,我们主要就是加上了籍贯。
其中我负责的《清代浙江集部总目》,是国家的一个后期资助项目,这个月29日会拿到书,出版社已经在公众号做了一个介绍,会出来。我们在编纂目录的时候,使用了一些技术,比如说Emeditor的全文搜索软件,这是西方开发的软件,对我们传统书目检索非常有用。它能够对几百部、上千部的书目作地毯式的搜索,且高量显示检索出来的结果。你输入一个书名,就能马上检索到其信息,收藏在哪个图书馆、什么版本?哪个大型的书目里面已经收录了,对我们提高效率是非常有用的。可以根据自己的要求,需要哪些信息,通过正则表达式可以搜索出来,这个对我们的编撰提高效率有很大的作用。另外使用了Excel或Access数据库一些功能,数据库可以进行匹配,比如说我们使用Excel里面的Vlookup,可以进行批量比较,能够知道哪些书是有的,哪些书是没有的,马上可以进行批量地检索,不需要一个一个地去查询,这是一个数据库的一个非常有用的功能。

因为我们的团队里面有6个人,经史子集丛书等,其他的老师都使用传统的方法,我使用数据库的方法,他们做好的数据,由我将其导入数据库。这样,就能批量查询,批量发现问题。比如说作者的籍贯,大家著录很不一致,这个只有数据库才能够快速地发现问题。数据库还有一个好处,就是可以排版。数据导出来,变成整齐划一的文本格式。如果你是在word里面处理的话,肯定会出现很多的问题,但数据库导出来文本格式,整齐划一,非常干净。
另外我们使用了Python技术,这是当前最流行的编程语言,语法不是很复杂,适合我们文科学者使用学习。我们在使用Python用来排索引,过去这个排索引只有出版以后,根据页码来排。现在可以在书出版前,用python对书名和序号排序。这样,索引就可以和正文一起出来,不需要根据页码来排序了。Python能够排书名或作者的音序、四角号码、笔画三种索引。另外,传统纪年和公元年的批量处理、新旧字型的转换、繁简字体的转换等,也可以用python处理。
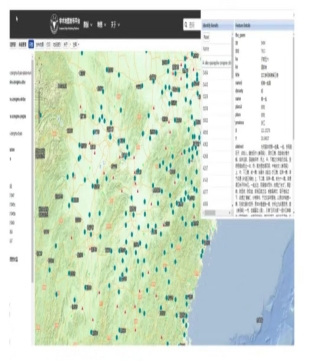
除了数据库和python技术的使用以外,我们还使用了GIS技术。因为我们编的这些目录著录了作者籍贯,有籍贯就有经纬度,就可以做好数据地图,发布在学术地图发布平台(http://amap.zju.edu.cn)上,供大家定位查询。学术地图发布平台是由浙江大学和哈佛大学共建的平台。上面已发布了很多的目录,譬如《四库全书总目》,就可以根据书名、作者、地点等信息定位查询某一个地方的著述。关于浙江的文古代献总目,我们已试着上传了杭州地区的目录。目录在地图上的定位查询,对研究地方文化是非常有用的。这里展示的,是我们做的一个集部数据的分布密度图,这是一个比较早的一个数据。从地图中,我们可以直观看到杭嘉湖地区的著述占了很大

第二,谈一下古籍整理与大数据技术。当前,大家接触到的文献形态,主要有纸本文献、金石文献、数字化文献、结构化数据几种。所谓的数字化文献,就是我们平常所说的电子书,包括图片格式和文本格式两种。所谓结构化数据,就是我刚才所说的数据库,如图书馆的在线目录、哈佛大学CBDB(中国历代人物传记资料库)等。CBDB里面有籍贯的人物都可以定位,有关系的人物可以可视化呈现。目前CBDB已与中国的上市公司中文在线(A股)合作,放在各大图书馆试用。浙大与哈佛共建的学术地图发布平台,也是一个结构化的数据。但是,我认为随着大数据技术的发展,文献整理一定会走向更高的发展阶段,即智慧化数据的阶段。

古籍智慧化数据的建设,取决于以下一些技术:
首先是基于机器学习的OCR技术。过去的OCR,只能识别排印本的书,印刷体文字,识别率非常高。但古籍的版刻体文字,识别率很低。随着机器学习、人工智能的技术进展,现在基于机器学习的OCR,识别古代版刻体字,准确率85-90%,大大加快古籍数字化文本的进程。

其次是古籍自动标点技术。谷歌里面有一个算法模型叫(BERT),大陆有多家的自动标点技术是根据BERT模型训练的。如包括北师大、北京龙泉寺等开发的自动标点技术,自动标点的准确率已达到85-90%。刚刚前两天,中华书局古联公司,已经发布消息,称他们的古籍自动标点平台已上线,大家免费测试30万字的数据。几百万的古籍,过去手工录入标点,要耗费学者几年的时间和精力,重复机械地做单调乏味的工作,现在只要几秒种,就完成这项工作的85-90%的工作量。
第三是分词技术。在计算机里面叫自然语言的处理,这个已经有很多开源的成果。如文言文的处理,就可以使用Jiayan这个库。使用Python,就可以将这个库引入。这对于机器标引古籍及可视化的词云呈现,都是很有用的。
第四是众筹包技术。所谓众包技术,就是打破时空界限,大家可以远程在同一个云平台做古籍整理的工作。平台提供扫描的图片和OCR后的文本,让用户远程进行线上校对整理。而且机器可以记录用户完成这项工作的时间、准确率,从而筛选出最适合古籍整理的专家。这样的话,项目就不局限于小团队,某个地方的人了。全世界各地的专家都可以参与这个工作。中华书局的古联公司已经采用了线上整理的众包技术。
我认为,所谓古籍的智慧化数据,就是利用知识图谱的理念以及大数据的技术,对古籍进行线上整理,供读者线上阅读。其模式和步骤是这样的:
第一步,扫描后的古籍图片,上传到服务器以后,经过OCR识别,然后再经过机器的自动标点,形成了一个初始的标点文本。
第二步,这个初始的标点文本,再经过众包的人工校对,形成一个干净正确的文本。
第三步,机器调用后台结构化数据,包括人名、地名、职官、科举、词典、诗韵等等的带有工具书性质的数据,对前台正确的文本进行机器标引。即前台的数据和后台的数据产生关联。
第四步,人工对机器标引的数据进行校对,形成正确的标引文本。机器的标引会有一些错误,比如“嘉定”,它既可以代表时间又可以代表地名,这个就需要人工的校对。
经过标引后的古籍,可以实现以下这些功能:
其一,可以计量统计,如词频统计、事件统计、人名统计、地名统计、书名统计等等。
其二,可以可视化。如人物的行迹图、分布图、社会网关系图、世系图、词云图等等。
其三,扫除阅读阅读障碍。因为关为文本关联了后台的词典,读者遇到不懂的词语,点击后即可明白其意。
其四,可以进行版本分析。由于一本书的版本,其图片和文本都在库里,随时可以调取比对。机器对不同版本的文本文字,能自动作出比对分析。
其五,可以进行诗韵、词韵的分析。因为后台有平水韵及词韵工具书,故能对诗歌的平仄进行自动分析。
其六,可以多语言切换。一首诗或一部小说,如果有不同的语种译本,都可以进行切换阅读。
其七,可以字体切换。现在古人的书法及篆刻,大多已数字化和识别,故读者阅读古书,可以选择书法或篆刻字体进行呈现,打破原来单一的版刻字体呈现模式。
总之,经过正确标引和关联的文本,读者阅读古籍,基本上就没有障碍了,且能看到可视化的分析性知识体系。古籍的智慧化数据建设,是一项浩大的工程,今后应该加大这方面的投入。以后出版社必须和高校合作,来共同打造这样一个平台,因为这里面涉及到非常专业的知识,需要学者的参与。而过去的古籍数据库,学者参与度是很少的。这样的平台建设好了以后,可以大大加快中国古籍的整理进程。譬如,《全明文》、《全明诗》这种工作,过去耗费了很长的时间,也才各自整理出版了三册。但是用这种古籍智慧化的数据理念和技术来处理,我们这一代人可以还看到《全明文》、《全明诗》项目的完成。我的报告就到这里,谢谢各位。
编辑|朱冰彦
原文来自微信公众号:浙江大学中文系 2021年9月15日
原文链接:
https://mp.weixin.qq.com/s/L8zAjeNObdRes8J0i4cLpg